Tuning Your Keras SGD Neural Network Optimizer
Author’s Note: This article does not explicitly walk through the math behind each optimizer. This article’s focus is to conceptually walk-through each optimizer and how they perform. If you don’t know what gradient descent is, check out this link before continuing with the article.
Stochastic Gradient Descent (SGD)
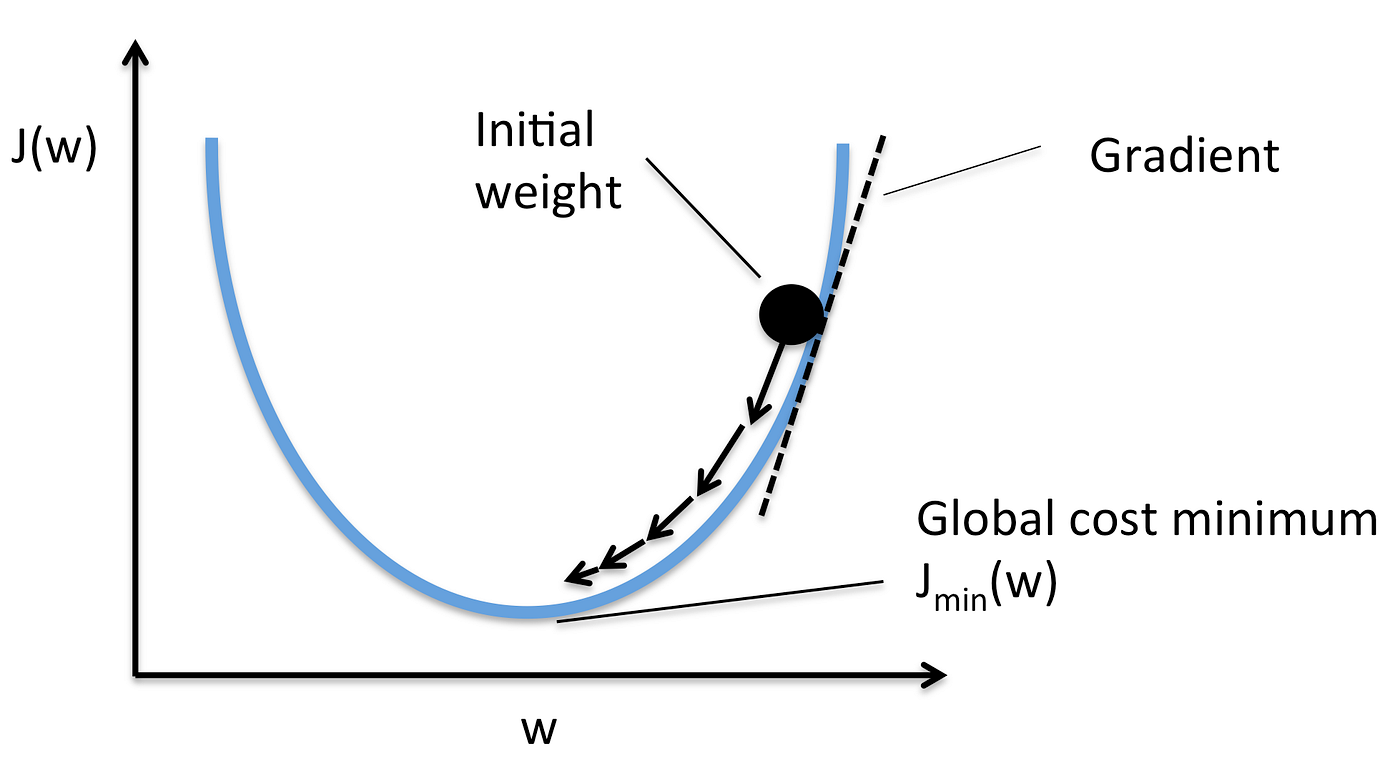
SGD is the default optimizer for the python Keras library as of this writing. SGD differs from regular gradient descent in the way it calculates the gradient. Instead of using all the training data to calculate the gradient per epoch, it uses a randomly selected instance from the training data to estimate the gradient. This generally leads to faster convergence, but the steps are noisier because each step is an estimate.
Momentum Optimization

Momentum optimization is an improvement on regular gradient descent. The idea behind it is essentially the idea of a ball rolling down a hill. It starts slow but picks up speed over time. The gradient for momentum optimization is used for acceleration rather than speed like in regular Gradient Descent. This simple idea is very effective. Think of what happens when regular gradient descent gets closer to a minimum. The gradient is small, so steps become really small and can take a while to converge. However, with momentum optimization, convergence will happen quicker because its steps utilize the gradients before it rather than just the current one.
Gradient Descent goes down the steep slope quite fast, but then it takes a very long time to go down the valley. In contrast, momentum optimization will roll down the valley faster and faster until it reaches the bottom (the optimum).*
Implementing momentum optimization is Keras is quite simple. You use the SGD optimizer and change a few parameters, as shown below.
optimizer = keras.optimizers.SGD(lr=0.001, momentum=0.9)The momentum hyperparameter is essentially an induced friction(0 = high friction and 1 = no friction). This “friction” keeps the momentum from growing too large. 0.9 is a typical value.
Nesterov Accelerated Gradient (NAG)

NAG is a variant of the momentum optimizer. It measures the gradient of the cost function slightly ahead of the direction of momentum rather than at the local position. This small difference allows for faster optimization because, in general, the momentum vector will be pointing towards the optimum. Consequently, each step is slightly more accurate than momentum optimization, and that small improvement adds up over time. Additionally, oscillations are reduced with NAG because when momentum pushes the weights across the optimum, the gradient slightly ahead pushes it back towards the optimum. Again, implementing this is simple.
optimizer = keras.optimizers.SGD(lr=0.001, momentum=0.9, nesterov=True)Conclusion
Adding two simple hyperparameters (only one needs tuning!) to the SGD optimizer can perform much faster. Knowing this is helpful for your neural network performance and understanding the continued evolution of neural network optimizers. There are better Keras optimizers available such as Adam, but SGD is the base level of Keras optimizers, and understanding the basics is essential.
